Managing & Scaling Big Data with DriveScale
 When I first looked at the lineup for Tech Field Day 12 (which was before I was asked to join), I was excited to see the list of companies. Some of them I know reasonably well, while there were a few on there that I had never heard of. DriveScale was one of them. When I wrote my ‘primer‘ post about them, it was a bit challenging as there is not a ton of information out there about them, but that also makes it fun. Having a bit of background on the presenting companies is great, but it is also engaging to learn about them during these presentations, in most cases from their founders or lead engineers.
When I first looked at the lineup for Tech Field Day 12 (which was before I was asked to join), I was excited to see the list of companies. Some of them I know reasonably well, while there were a few on there that I had never heard of. DriveScale was one of them. When I wrote my ‘primer‘ post about them, it was a bit challenging as there is not a ton of information out there about them, but that also makes it fun. Having a bit of background on the presenting companies is great, but it is also engaging to learn about them during these presentations, in most cases from their founders or lead engineers.
WHO IS DRIVE SCALE

Currently, DriveScale sits at 21 employees, 17 of which have spent some time at Sun Microsystems in the past. Going into this, I knew that DriveScale was made up of some extremely smart people, but I don’t think I had an appreciation for the impact these folks have had on the industry. Gene Banman (CEO), took the time to give us a bit of company history, and it included interesting tidbits such as:
- Tom Lyon was employee #8 (!) at Sun Microsystems where he worked on NFS & the SPARC architecture. He also invented IP Switching at Ipsilon Networks;
- Satya Nishtala was a Technology Fellow at Nuova Systems, which Cisco purchased and turned into the UCS server line and Nexus switches;
- Duane Northcut conceived and led the development of the Sun Ray product, one of the first examples of modern-day VDI thin clients.
WHAT DO THEY DO
In hindsight, my ‘primer’ post was a pretty good overview (not trying to toot my own horn) – DriveScale essentially builds a hardware system which allows you to take existing compute and storage resources, and manage it more efficiently. Its primary use-case is for Big Data applications, such as Hadoop.

We were fortunate enough to have a great hardware overview with Sataya, where some more details were revealed. The backside of the units consists of power supplies, SAS interfaces, 10 GbE interfaces, and four DriveScale Ethernet to SAS adapters. Those last ones are where the magic happens when combined with DriveScale’s management software. All of the components are off the shelf, commodity components. Ironically, the network processor was made by Broadcom, the SAS controller by LSI, and the PCI Express switch by LSX. The reason for the irony: they are all part of Avago Technologies now. The cost on each of these is roughly $6000 USD.
For the sake of future planning, the front of the chassis can also accommodate 10 NVMe SSD drives. At the moment they are not populated, but the idea is that in a future release a customer can add some storage in there, carve it up as needed, and use it for caching. The caching would be managed via DriveScale in a transparent manner (as opposed to configuring it in the application).
USING DRIVESCALE
In order to get going with DriveScale, you’ll need to get their adapter into your rack and hook some disks up to it. The disks will sit in a JBOD unit (the demo we saw had 60 disks attached), and if you desire,through the UI you can go down to the individual details of each disk (e.g. make, model, firmware, etc). At the moment there is no management piece to handle tasks like firmware upgrade for the drives. That being said, there aren’t any issue with mixing drive makes or models. You can even put SATA drives in there if you wish, you’ll just need an interposer.

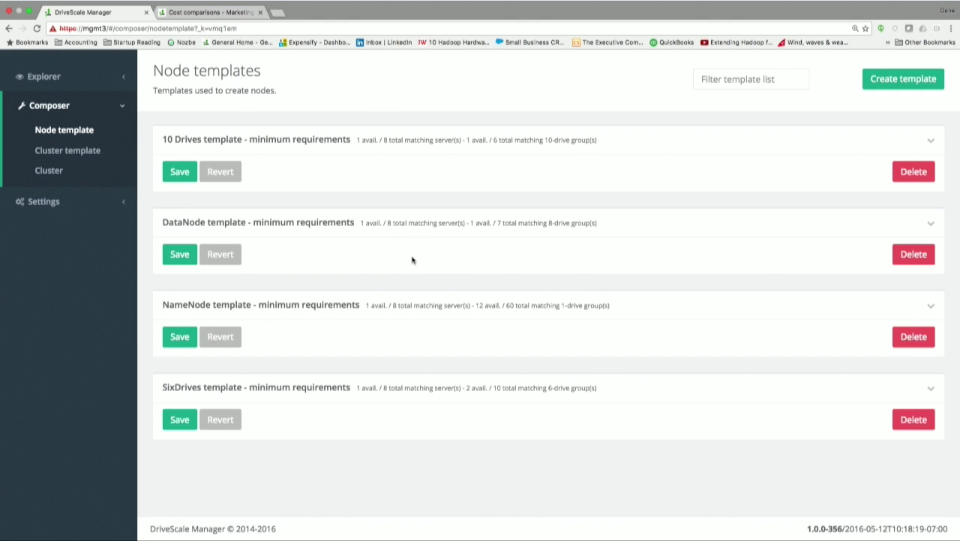
On the software side, templates drive a lot of the processes. You can define a template for a node, where you setup requirements for things such as CPUs, number of drives, and RAM. Next up, you can create a cluster template. You can assign nodes to the cluster via templates, or if you have some favourites, you can specify that it must contain a number of named nodes, based on a range (which would be one). With those two templates setup, you can then go create a cluster by choosing what templates to use, and a new cluster will be setup. By using this template approach, you can get fairly granular. First of all, it’s a great way to scale things easily – not having to go through the same configuration steps each time. Secondly though, it also lets you handle those ‘snowflake’ instances where you might need to make sure that a compute cluster is physically close to some JBODs, in which case the named node might come into play.
CLOSING THOUGHTS
DriveScale may be a very attractive option for Big Data organizations looking to ease some management burden. The fact that businesses can leverage their existing investments in compute and storage is definitely a point to look at. Bundled with the fact that you’ll be able to use DriveScale’s software to tie together resources across multiple racks may also lead to greater efficiencies.
Hadoop’s version 1.0 release is five years old (almost to the day) and DriveScale has been around for three years of those years. What I like about what I saw was they identified a problem (efficiently managing and scaling resources) and they provided both a hardware and software solution to do this. Their adapter essentially makes the existing hardware a commodity, while their software ties it all together. As Big Data grows, it will be interesting to see how DriveScale keeps up.
Disclaimer: I was invited to participate in Tech Field Day as a delegate. All of my expenses, including food, transportation, and lodging were covered by Gestalt IT. DriveScale did provide all delegates with a small gift bag, which consisted of DriveScale branded socks and a DriveScale branded mug filled with green LifeSavers. I did not receive any compensation to write this post, nor was I requested to write this post. Anything written above was on my own accord.


